
Abstract
Large vision language models, such as CLIP, demonstrate impressive robustness to spurious features than single-modal models trained on ImageNet. However, existing test datasets are typically curated based on ImageNet-trained models, which aim to capture the spurious features inherited in ImageNet. Benchmarking CLIP models based on the ImageNet-oriented spurious features may not be sufficient to reflect the extent to which CLIP models are robust to spurious correlations within CLIP training data, e.g., LAION. To this end, we craft a new challenging dataset named CounterAnimal designed to reveal the reliance of CLIP models on realistic spurious features. Specifically, we split animal photos into groups according to the backgrounds, and then identify a pair of groups for each class where a CLIP model shows high-performance drops across the two groups. Our evaluations show that the spurious features captured by CounterAnimal are generically learned by CLIP models with different backbones and pre-train data, yet have limited influence for ImageNet models. We provide theoretical insights that the CLIP objective cannot offer additional robustness. Furthermore, we also re-evaluate strategies such as scaling up parameters and high-quality pre-trained data. We find that they still help mitigate the spurious features, providing a promising path for future developments.
CounterAnimal Dataset
Previous works often claim that CLIPs can resolve the distribution shifts, but their adopted datasets to test the effective robustness are primarily designed for the ImageNet-based models. It may not fully reflect the cases of CLIPs. Therefore, we collect a real-world dataset named CounterAnimal, containing spurious features for animal photos. Data therein are separated into two groups:
- The common group contains photos of animals in frequently appeared backgrounds.
- The counter group contains photos of animals in less commonly yet still plausibly appeared backgrounds.
The common group captures some real-world biases that CLIPs-trained on web-scale data may naturally inherit. Therefore, by comparing the performance on the common group against that on the counter group, one can quantify to what extent CLIPs rely on spurious features.

Figure 1. Examplary photos with the object label of ice bear, further separating into common and counter groups based on different backgrounds (i.e., snow and grass). The performance drop in zero-shot inference by CLIP-LAION400M-ViT/B/32 is significant, from common (97.62%) to counter (70.91%).
We take iNaturalist as our raw data source, manually labeling objects (i.e., animal names) and backgrounds (e.g., grass and snow) to find spurious features that can hinder the robustness of CLIPs. The resulting dataset has 7,174 common photos and 5,926 counter photos, covering a total of 45 animal classes as a subset of the ImageNet-1K label space. Our dataset can be downloaded by the following link. We further summarize the object names as well as the background names for common and counter parts.
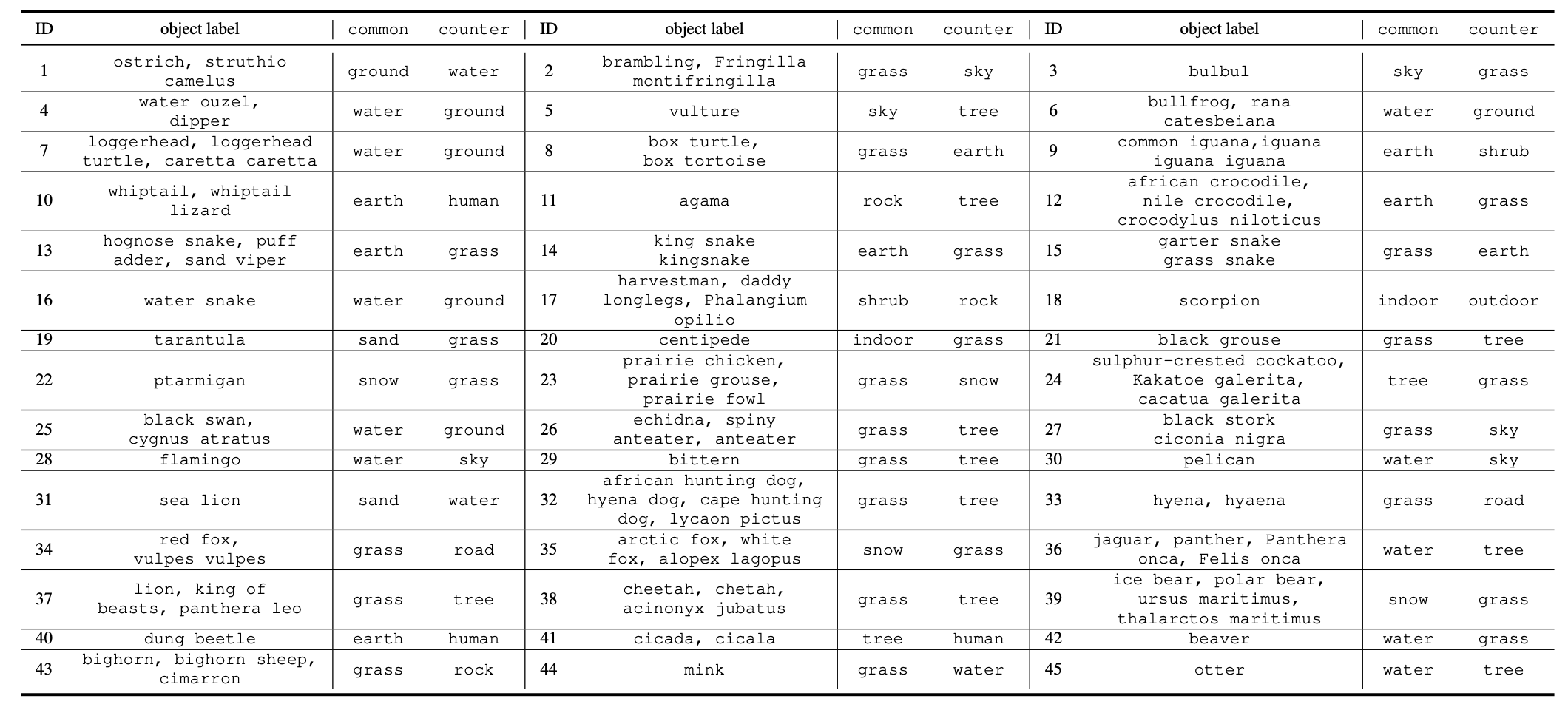
Table 1. The full object names as well as the background names of common and counter groups. The full names of the labels are presented following the fashion of the ImageNet-1K dataset.
Results on our CounterAnimal Dataset
We evaluate various learning schemes on CounterAnimal and employ two evaluation setups to fit different learning setups:
- 1 vs 1000 setup: using the full ImageNet-1K class names as the candidate label space.
- 1 vs 20 setup: using the top-20 most confusing classes for the CLIP model as the candidate label space.
We summarize the common and counter performance on counteranimal across various learning schemes, including CLIP pre-trained models, ImageNet models, and more advanced LVLMs such as MiniGPT4 and LLaVA. Our experiments also consider various pre-train datasets for CLIPs and various backbones models.
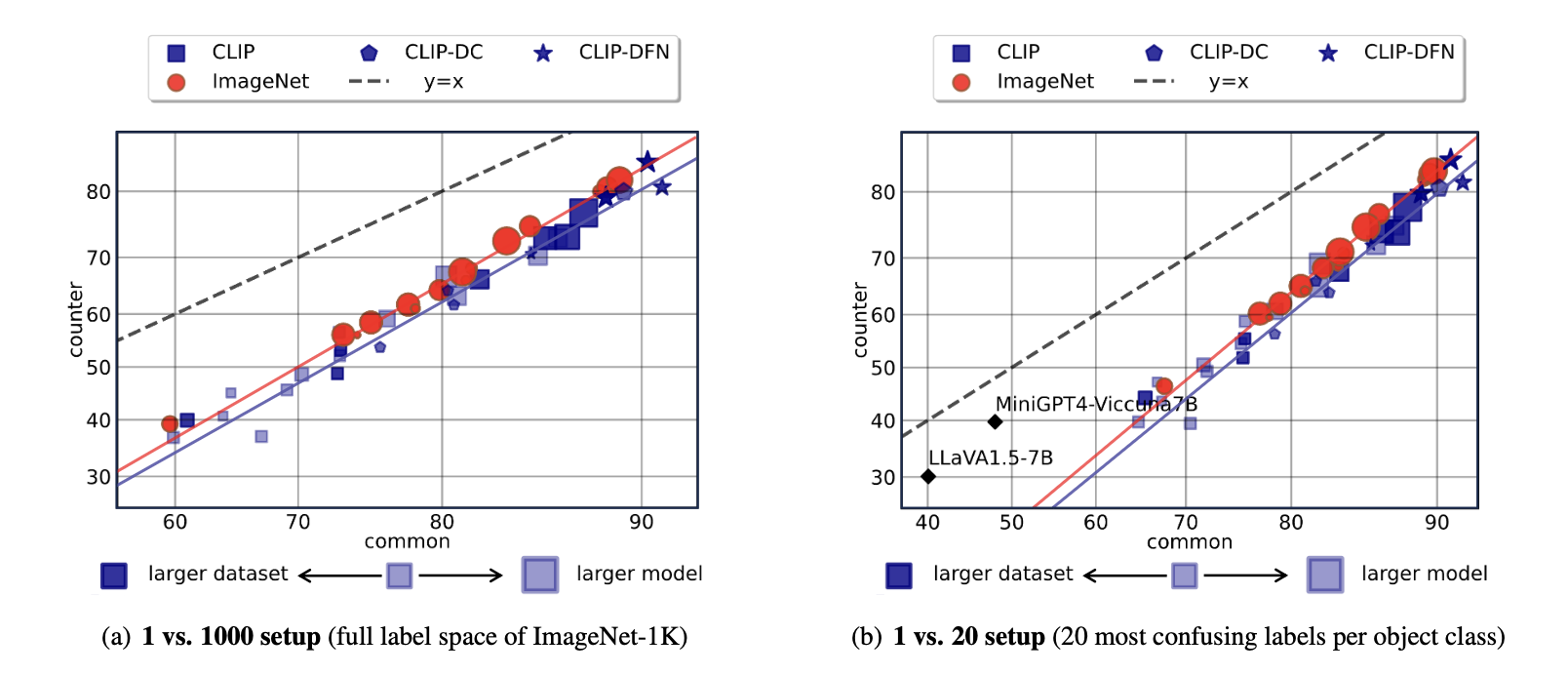
Figure 2. The common vs counter performance for CLIPs, ImageNet models, and more advanced LVLMs. The size of markers indicates the backbone scales and the color shade of markers indicates the pre-train dataset scales. We depict the prefect trend (i.e., y=x) where models donot learn any spurious correlations, linearly fit the trends for CLIPs and ImageNet models; highlight the CLIP models pre-trained on two high-quality datasets, i.e., DataComp (CLIP-DC) and DFN (CLIP-DFN).
We highlight some of the key observations as follows.
CLIP models still learn spurious correlations. We observe that CLIP models exhibit non-trivial performance drop from common
to counter groups. It implies that CounterAnimal characterizes some general spurious correlations that are commonly present in
large-scale real-world multimodal datasets. Moreover, CLIP may still learn the spurious features in real-world pre-train datasets.
We present several examples of the CLIP models for the performance drop.
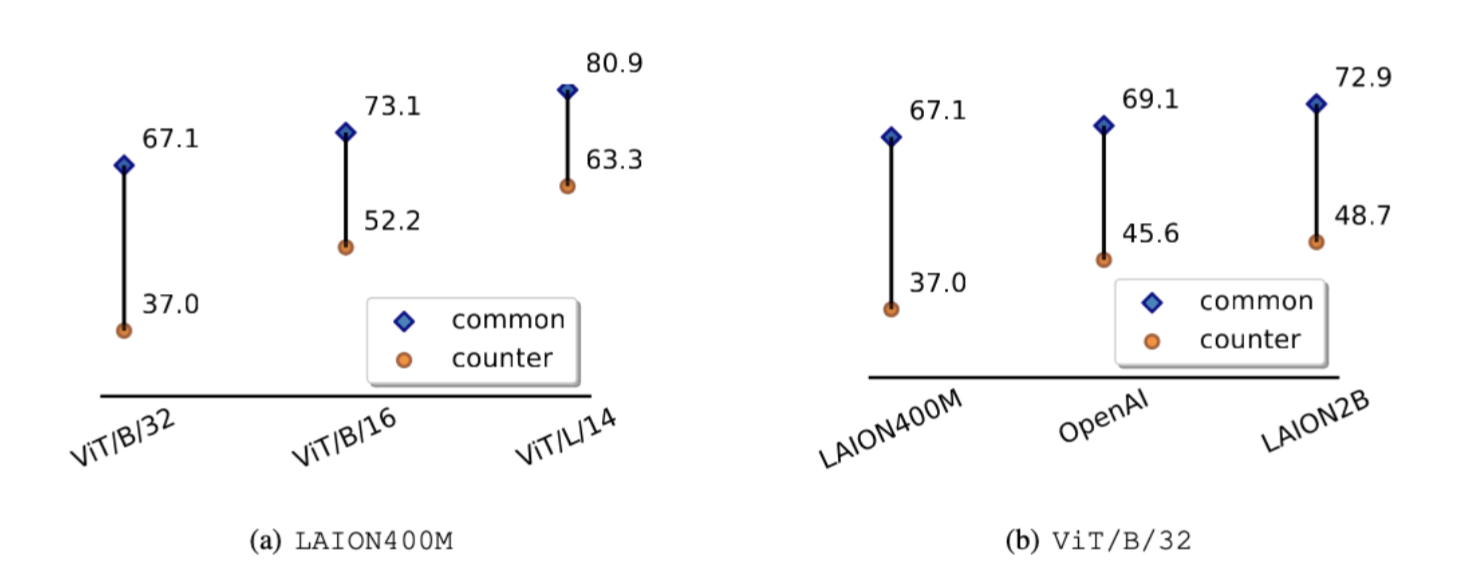
Figure 3. Comparison of the common and counter groups for varying CLIP setups: a) Fixing the pre-train dataset to be LAION400M and b) fixing the backbone to be ViT/B/32. The 1 vs 1000 results are given.
ImageNet models are more robust to spurious features in CounterAnimal. Compared with CLIPs, we find that ImageNet models exhibit better robustness to the presented spurious correlations. It is evident from Figure 2 by the superior performance of ImageNet models on the counter groups and similar common performance with respect to CLIPs. Our findings contrast with previous studies that evaluated distribution shifts using ImageNet variants, indicating that the CLIP does not necessarily generalize better than ImageNet models. We illustrate two comparison with fixed backbones as follows.
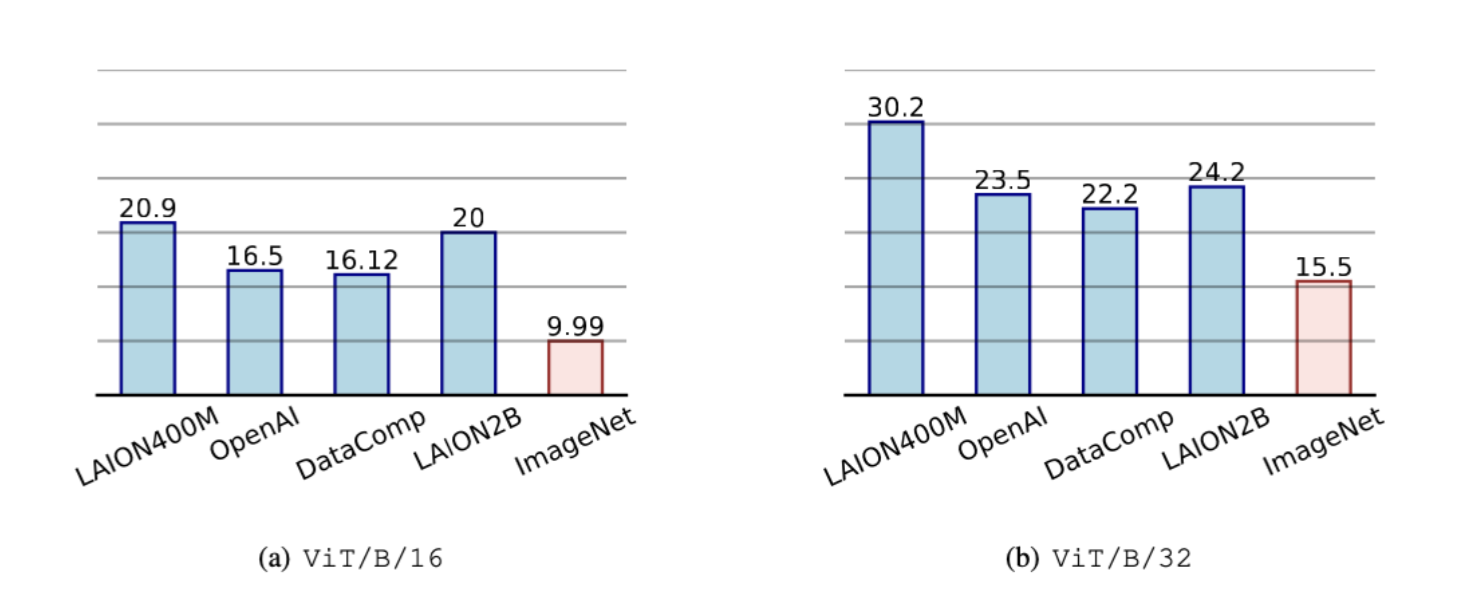
Figure 4. Comparison between CLIPs and ImageNet Models. The 1 vs. 1000 results are given.
Larger CLIPs are more robust. in Figure 2, we use sizes and color shades of markers to indicate the scales of backbones and pre-train datasets, respectively. Overall, larger CLIP backbones (i.e., larger markers) can improve the counter performance, implying that scaling up backbones may enhance robustness. In contrast, increasing the scale of the pre-train dataset (i.e., darker markers) does not yield the same improvement, implying that collecting more data alone cannot rectify much bias. We present several comparison with either fixed pre-train datasets and fixed backbones as follows.
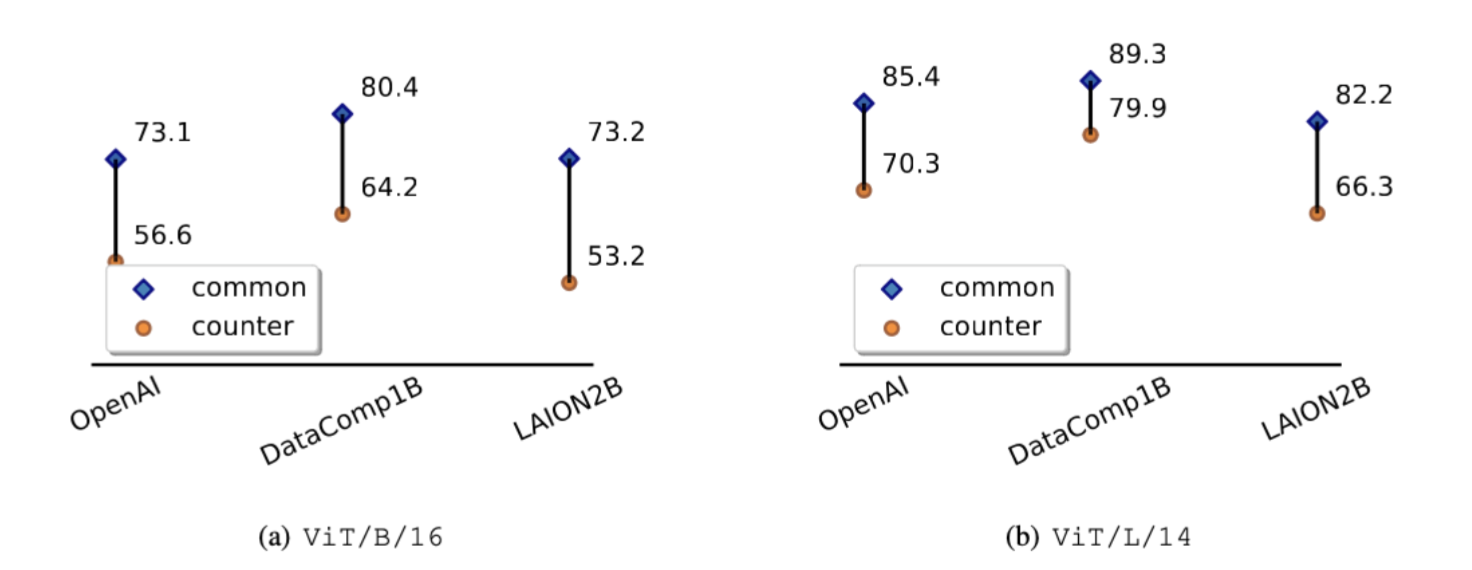
Figure 5. Comparison with different pre-train datasets and fixed backbones. 1 vs. 1000 results are given.
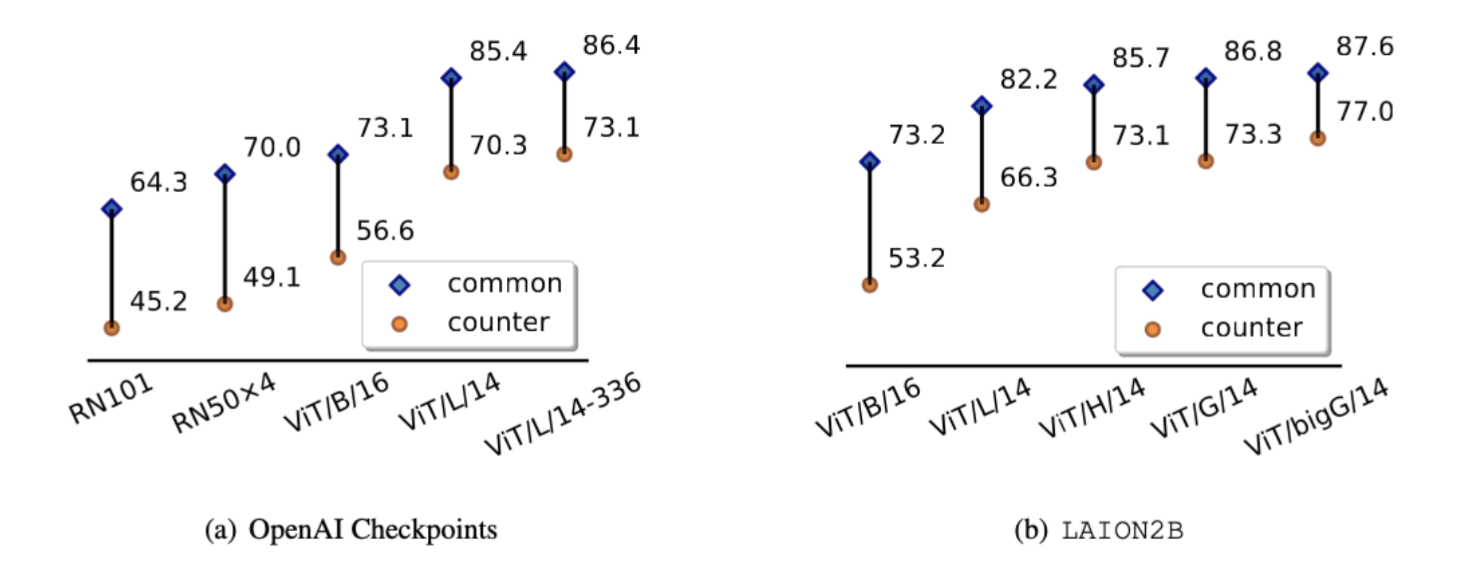
Figure 6. Comparison with different backbones and fixed pre-train datasets. 1 vs. 1000 results are given.
CLIP model pre-trained on high-quality data are more robust. We discern two classes of CLIPs in Figure 2, a) those pre-trained on high-quality datasets, i.e., DataComp (CLIP-DC) and {DFN}~\citep{fang2023data} (CLIP-DFN), and b) those pre-trained on other datasets that lack stringent curation (CLIP). As we can see, CLIPs pre-trained on high-quality data generally exhibit superior robustness, suggesting that improving data quality is still a promising way against spurious features.
CLIP objective may not offer additional robustness. To better understand the observed phenomena, we present a theoretical analysis of why CLIPs rely on spurious features.

Theorem 1 implies that, once there exists a relatively strong correlation between the object captions and the parts of image backgrounds, CLIPs will learn to align the backgrounds, i.e., spurious features, with object captions. The theoretical analysis also align with our empirical findings.
Contact
Welcome to check our paper for more details of the research work. If there is any question, please feel free to contact us.
If you find our paper and repo useful, please consider to cite:
@inproceedings{
counteranimal,
title={Do {CLIP} Models Always Generalize Better than ImageNet Models?},
author={Qizhou Wang and Yong Lin and Yongqiang Chen and Ludwig Schmidt and Bo Han and Tong Zhang},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=wWyumwEYV8}
}